Building Our Own CDN
Brief History
- Pre-2011: Business contracts were maintained with external CDN companies.
- Traffic Allocation: Guaranteed each external CDN a stable share of the streaming traffic.
- Simplicity of Steering: All of the Video CDN Steering logic fit entirely within:
- 5 Java Classes
- ~60 lines of code
- Scale: Handled 1/3 rd of peak internet traffic in the US.
- Strategic Shift: A decision was made to build an in-house CDN.
Predictable Viewing Patterns
The foundational architecture of this custom CDN system relies on a predictable data distribution rule: a small fraction of content generates the bulk of internet traffic.
Bytes Streamed
^
| *
| *
| *
| *
| * * * * * * * * * * * * *
+-----------------------------------> Content Rank
Not a Traditional CDN
Unlike standard CDNs that use on-demand caching mechanisms, this system employs unique optimization policies:
- Predetermined Placing: Proactive content placement instead of reactive on-demand caching.
- Precise Traffic Steering: Steers customers precisely to specific machines at Internet Exchanges (IXs) & Internet Service Providers (ISPs).
- No Global Replication: There is no guarantee that every machine has every file available.
- Popularity Computation: Utilizes highly granular and accurate popularity computations, leading to significant efficiency gains.
Serving Machine Selection Process
- Network Proximity: Pick machines that are routable and close based on route prefixes and network cost.
- Health and Metrics: Filter for machines that are stable over time, healthy, capable of taking more traffic, and dynamic enough to respond to major changes in popularity.
- Content Availability: Select machines that explicitly hold the requested content.
Machines on the Internet
The CDN categorizes infrastructure deployment locations into distinct topological layers:
| Machine Location Layer | Network Characteristics & Routing | Content Strategy |
|---|---|---|
| Embedded in ISP | Closest to the ISP’s customers from a network topology perspective. Likely not routable from other ISPs. | May not house all content. |
| Internet Exchange (IXP) - Direct Peering | Direct peering established between the ISP Data Center and the IXP. May not be routable from other ISPs. | - |
| Internet Exchange (IX) - Transit | Requires transit routing between the IX and the ISP Data Center. Costs extra money ($\$\$\$) for the transit link. Widely routable. | Highly useful as a final fallback and holds the full content catalog. |
Architecture v1
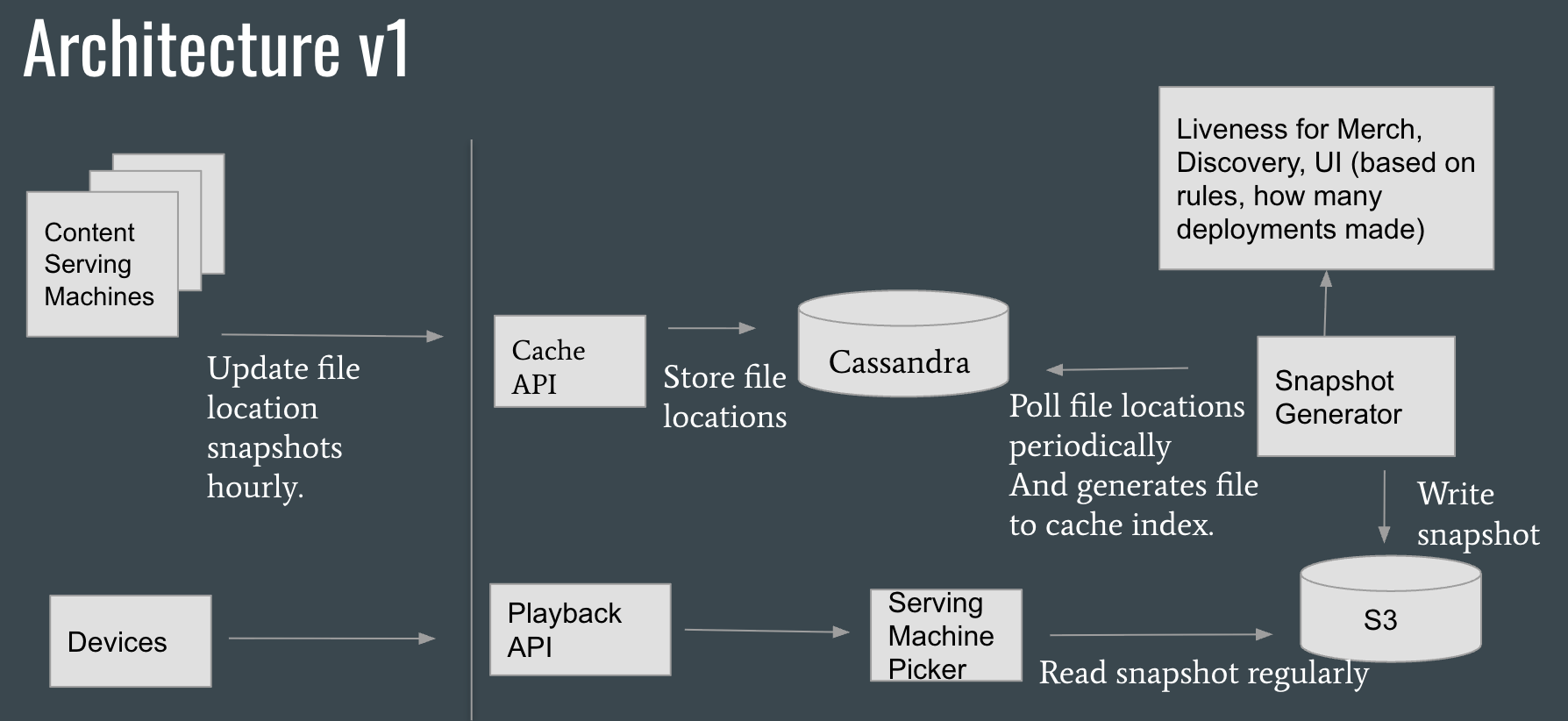 The system coordinates communication between edge content serving units, state databases, and customer playback endpoints:
The system coordinates communication between edge content serving units, state databases, and customer playback endpoints:
- Content Serving Machines update file location snapshots hourly.
- The Cache API receives these locations and saves them into a distributed Cassandra database.
- A Snapshot Generator periodically polls file locations from Cassandra to generate a unified cache index, which it writes as a snapshot to Amazon S3.
- On the consumer side, client Devices interact with the Playback API.
- The Serving Machine Picker regularly reads the pre-compiled snapshots from S3 to optimally route playback traffic.
Placing Content on Machines
Popularity Curve Strategy
- Geographic Aggregation: Popularity is computed at a country level (or broader regional scopes). Many distinct clusters inside a given country subscribe to the exact same country-level popularity feed.
- Smoothing Filter: Curves are mathematically smoothed over N past days using an Exponential Weighted Moving Average (EWMA) formula.
- Hardware Tiering: Highly popular content is explicitly placed on fast Flash/SSD arrays, while the remainder resides on high-capacity Hard Disk Drives (HDDs) to prevent overloading HDD hardware limitations.
The Impact of Prediction Misses
When mapping actual storage allocation against predicted offload performance, discrepancies surface:
- Predicted Performance: 400 TiB allocated storage was expected to hit a 99.6% network traffic offload rate.
- Actual Performance: 400 TiB allocated storage achieved only a 96% network traffic offload rate.
Does a Small 3.6% Prediction Miss Matter?
Yes, it matters profoundly due to system leverage effects. Consider a cluster processing 5 Tbps of total edge traffic:
- Predicted HDD load: $0.4%$ of 5 Tbps = 20 Gbps (expected to be served from HDD storage).
- Actual HDD load: $4%$ of 5 Tbps = 200 Gbps (actual traffic demanded from HDD storage due to the misprediction).
- Hardware Limit: The cluster’s total HDD capability = 15 machines times 20 HDDs times 0.5 Gbps = 150 Gbps.
Consequences of the Bottleneck
- Traffic Loss: The HDDs are asked to deliver 200 Gbps but max out at 150 Gbps. This results in losing 50 Gbps of total traffic due to being strictly throttled by HDD read speeds.
- Thermal & Hardware Strain: Edge machines run hot because hard drives are pushed to peak capacity continuously, tipping the system over safe thresholds.
- Under-utilization: Expensive, high-performance SSD infrastructure remains under-utilized.
- QoS Degradation: Quality of Service (QoS) degrades significantly for all customers streaming content from hard disks.
- Financial Costs: Diverting massive chunks of traffic to distant alternative clusters incurs substantial external transit monetary costs ($$$$) and threatens to saturate ISP links.
Mitigation
To resolve this widespread systemic issue, the architecture transitioned to Granular, Per-Cluster Prediction modeling instead of broad country-level aggregations.
Housekeeping on Content Serving Machines
Content Allocation
- Minimizing Churn: As day-over-day popularity queues shift, content allocation strategies must prevent heavy internal churn on machines within a cluster.
- Algorithmic Routing: Consistent Hashing is employed to cleanly distribute files to target cluster nodes.
Content Deletion
- Soft Deletion: When a file is scheduled for removal, it is initially “soft-deleted”. This buffer seamlessly accommodates state propagation delays across the network.
Content Fill Time
- Off-Peak Operations: Edge machines perform content hydration/cache filling exclusively during off-peak hours.
- Cost Efficiency: Since network bandwidth pricing models calculate charges using 95th percentile traffic metrics, scheduling cache fills during low-use windows prevents driving up operational bills.
Architectural Enhancements (v2)
To achieve per-cluster optimizations and sub-hour state synchronization, enhanced real-time streaming tools were introduced into the data control plane:
- Cache Tracking: Caches report file locations via the Cache API.
- Message Streaming: Updates pass into Kafka (equipped with MirrorMaker) for durable event streaming.
- Stream Processing: Apache Flink ingests Kafka events, outputting state data through structured checkpoints directly to Amazon S3.
- High-Performance Query Layer: Flink keeps an low-latency index stored in MemCache (backed by persistent disk storage).
- Device Playback: Consumer Devices ping the Playback API, allowing the Cache Picker to execute ultra-fast lookups against MemCache instead of pulling heavy file snapshots over S3.
- Media Ingestion: A Media Pipeline feeds directly into a Liveness Generator, which actively communicates with MemCache using routine full scans to guarantee global catalog accuracy.